- 作者 :Xcbeyond
- 发表于 :2025-12-21 21:10:36
- 分类 : Kubernetes
在 Kubernetes 中,健康检查(Probe) 是保障服务稳定运行的核心能力之一。
但在实际使用中,Readiness 和 Liveness 经常被混用、误用,轻则导致流量抖动,重则引发 Pod 频繁重启、雪崩效应。
本文将从设计目的、工作机制、差异、示例、最佳实践、进阶玩法全方位讲解,并结合 Spring Boot 案例给出完整配置。
1、为什么需要 Readiness 和 Liveness?
在没有健康检查之前,K8S 只能知道:
Pod 是否存在、容器是否在运行
但这远远不够:
- 应用启动慢,但容器已经 Running
- 应用卡死(死循环、线程阻塞),但进程还活着
- 依赖数据库 / MQ 不可用,但服务仍在对外接流量
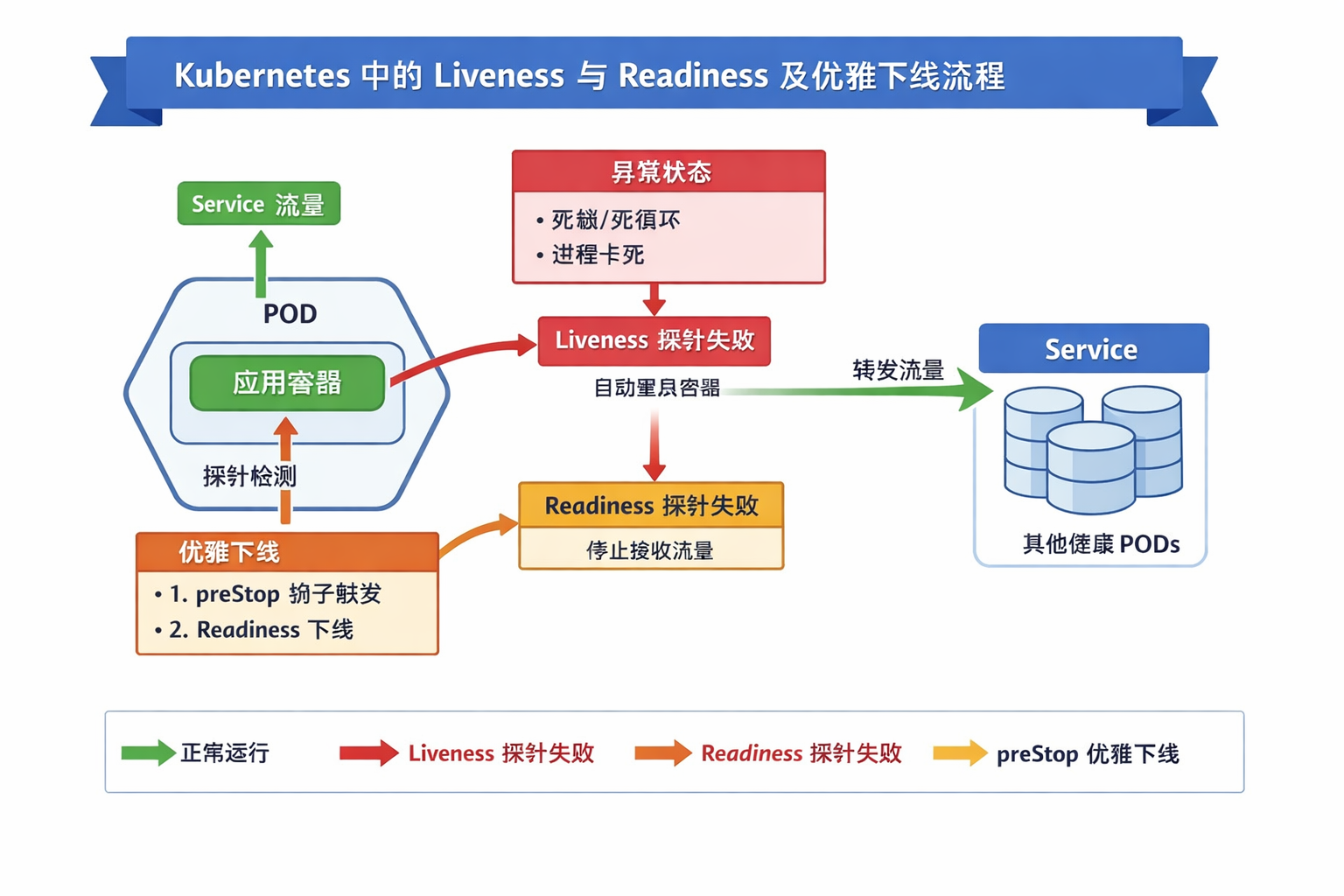
Readiness 与 Liveness 就是为了解决这些问题而设计的。
2、Readiness Probe:我现在能接流量吗?
2.1 核心作用
判断 Pod 是否“就绪”接收流量
- ❌ 失败 → Pod 从 Service Endpoints 中移除
- ✅ 成功 → Pod 重新加入负载均衡
- ⚠️ 不会重启容器
2.2 典型使用场景
- 应用启动过程中(Spring Boot 初始化)
- 依赖的数据库 / Redis / MQ 不可用
- 服务被限流、熔断、自动降级
- 优雅下线(配合 preStop)
2.3 示例配置(HTTP 探针)
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
2.4 Spring Boot Readiness 实现示例
@Component
public class ReadinessHealthIndicator implements HealthIndicator {
@Override
public Health health() {
if (dbAvailable() && cacheAvailable()) {
return Health.up().build();
}
return Health.down().withDetail("reason", "dependency unavailable").build();
}
}
- 依赖异常 → readiness down
- 服务仍可存活,等待依赖恢复
- 结合 preStop 实现优雅下线
3、Liveness Probe:我是不是“活着”?
3.1 核心作用
判断容器是否处于“不可恢复的异常状态”
- ❌ 失败 → 直接重启容器
- ✅ 成功 → 正常运行
3.2 典型使用场景
- 线程死锁
- 死循环
- 内存泄漏导致应用无响应
- JVM 卡死但进程未退出
⚠️ 不适合:
- 数据库不可用
- 外部依赖短暂异常
3.3 示例配置(HTTP 探针)
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 2
failureThreshold: 3
3.4 Spring Boot Liveness 示例
@Component
public class LivenessHealthIndicator implements HealthIndicator {
@Override
public Health health() {
if (threadPoolAlive() && mainLoopAlive()) {
return Health.up().build();
}
return Health.down().build();
}
}
4、Readiness vs Liveness 核心区别
| 维度 | Readiness | Liveness |
|---|---|---|
| 关注点 | 能否接流量 | 是否需要重启 |
| 失败后果 | 从 Service 摘除 | 容器重启 |
| 是否影响 Pod 生命周期 | 否 | 是 |
| 适合依赖异常 | ✅ 是 | ❌ 否 |
| 适合进程死锁 | ❌ 否 | ✅ 是 |
一句话总结:Readiness 控制“流量”,Liveness 控制“生死”
5、Readiness + preStop 实现真正的优雅下线
在滚动升级或缩容时,如果 Pod 立即被删除,可能导致请求被中断。 结合 Readiness + preStop 可以实现 优雅下线:
- preStop Hook 触发 Pod 进入“即将退出”状态
- Readiness Down → Pod 被从 Service 中摘除,停止接流量
- 等待请求完成 → 再真正停止容器
示例配置:
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"]
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
sleep 10表示给 Pod 10 秒时间处理现有请求- Readiness Down 后不会再接新流量
6、结合 Spring Boot Actuator 的完整配置
Spring Boot 2.x 提供了 Liveness / Readiness 指标分离:
management:
endpoints:
web:
exposure:
include: health
health:
livenessstate:
enabled: true
readinessstate:
enabled: true
/actuator/health/liveness→ 只关注进程/actuator/health/readiness→ 关注依赖服务(DB、Redis、MQ 等)- 配合 K8S 探针使用,保证健康检查逻辑清晰、准确
7、生产环境探针参数调优指南
| 参数 | 建议值 | 说明 |
|---|---|---|
| initialDelaySeconds | Liveness: 60~120sReadiness: 10~30s | 应用启动慢,避免误判 |
| periodSeconds | 5~15s | 探针检查间隔 |
| timeoutSeconds | 1~5s | 请求超时 |
| failureThreshold | 3~5 | 连续失败次数才判定失败 |
原则:
- Liveness → 慎重重启,避免雪崩
- Readiness → 快速摘除不健康 Pod,保护流量
- 对慢启动的 Java/Spring Boot 应用,initialDelaySeconds 一定要比启动时间长
8、总结
- Readiness = 流量开关
- Liveness = 生死判定
- 优雅下线 = Readiness + preStop
- 生产调优 = initialDelaySeconds / periodSeconds / failureThreshold 配合应用特性
用好 Readiness 和 Liveness,是 Kubernetes 可靠性和服务稳定性的基石。