
一、前言
作为程序员的你,数据库作为一门必修课,而 MySQL 数据库毫无疑问已经是最常用的数据库了。系统的稳定、高效、高并发等指标,很大程度上取决于数据库性能是否够优,可见性能优化的重要性,这也就不难理解各位在任何一场面试中都会被问及到数据库调优相关的问题。
因此,这就是我为何考虑写该系列文章的主要原因,希望该系列文章(MySQL性能优化)能够给你带来收获,让你更系统、更全面的掌握 MySQL 性能优化的技能、技巧。该系列文章将会持续分享、更新,如果觉得现在或者将来可能对你有用,不妨持续关注、收藏。
在 MySQL 性能优化之前,你有必要重新再认识下 MySQL,便于后续更容易理解 MySQL 性能优化中涉及到的知识点。本文将从 MySQL 架构、核心问题来针对性展开讨论,这也将是 MySQL性能优化 系列文章的开篇之作。
二、MySQL 逻辑架构
想深入探究 MySQL 之前,有必要了解一下 MySQL 的逻辑架构,逻辑架构图如下:
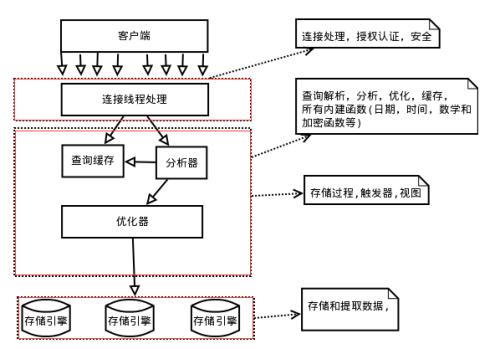
MySQL 的逻辑架构中,分为三层,如上图红色虚线框的三部分。
最上层架构并不是 MySQL 所独有的,大多数基于客户端/服务器形态的系统或者服务,都有类似的架构,其中包含 MySQL 的连接处理、授权认证、安全控制等等。
第二层架构是 MySQL 中最为核心的部分,其中包括查询解析、分析、优化、缓存以及所有的内置函数(如:日期、时间、函数等),所有跨存储引擎的功能都在这一层实现,例如:存储过程、触发器、视图等。
第三层架构是存储引擎。存储引擎负责 MySQL 中数据的存储和提取,类似与 Linux 系统下的各种文件系统一样,不同存储引擎都有各自的优势和劣势,不同场景可选择不同的引擎。不同存储引擎之间是不会相互通信的,只是简单地响应上层的请求。
三、如何控制高并发的读写?
无论何时,对于数据库而言,高并发的读写操作是很常见的,针对同一条记录在同一时刻进行修改、查询操作,都会产生并发控制的问题,处理不当将会出现大量的脏数据。那么,如何控制高并发的读写操作呢?
1.读写锁
在我们学习任何一门语言时,针对处理并发问题都会选择锁机制来解决并加以控制,这也是解决并发控制的经典方法,MySQL也不例外。在MySQL处理高并发的读或者写时,可以通过实现两种类型的锁来解决,这两种类型的锁通常被称为共享锁(Shared lock)和排他锁(exclusive lock),其实就是大家叫的读锁(read lock)和写锁(write lock)。
读锁,是共享的,也就是说是互相不阻塞的。多个请求在同一时刻可以同时读取同一条记录,而互不干扰。
写锁,是排他的,也就是说一个写锁会阻塞其他的写锁和读锁,避免在写的过程中进行读、再写的操作,这更是出于安全的考虑,只有这样才能确保数据的准确、干净。在数据库中,每时每刻都在发生锁定,当某次请求修改数据时,MySQL 都会通过锁来防止其他请求读取同一数据。
2.锁策略
有了锁的机制,就能更好的控制高并发的读写操作,我们都知道锁也是有范围的,锁定对象范围的选择,更具有挑战性。尽量只锁定需要修改的部分数据,而不是所有数据,这也是选择锁定对象范围最想满足的。锁定范围越精确,锁定的数据量就越小,则系统的并发程度越高,加锁本身消耗的资源也就越小。
上述提到的无非就是设定锁的粒度,而MySQL则提供了多种选择,每种MySQL存储引擎都可以实现自己的锁策略和锁粒度。下面将介绍两种最常用的锁策略。
2.1 表级锁(table lock)
表级锁是 MySQL 最基本的锁策略,并且是开销最小的策略,它会锁定整张表。一个请求在对表进行写操作(插入、修改、删除等)前,需要先获得写锁,此时会阻塞其他请求对该表的所有读写操作。只有没有写锁时,其他请求才能读取并获得读锁,读锁之间是不相互阻塞的。
尽管存储引擎可以管理自己的锁,而且 MySQL 本身还会使用各种有效的表级锁来实现不同的目的。例如,诸如 ALTER TABLE 之类的语句就使用了表级锁,而忽略存储引擎的锁机制。
开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
表级锁,更适用于以查询为主,只有少量按索引条件更新数据的应用。
2.2 行级锁(row lock)
行级锁可以最大程度地支持并发处理(同时也带来了最大的锁开销)。
开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。
行级锁,更适合于有大量按索引发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理系统。
四、MySQL 存储引擎是怎样的?
在文件系统中,MySQL 将每个数据库(即:schema)保存为数据目录 data 下的一个子目录。创建表时,MySQL 会在数据库 data 目录下创建一个和表同名的 .frm 文件来保存表的定义。
不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在 MySQL 服务层统一处理的。
可以使用 show table status like '表名' \G 命令来查看表的存储引擎以及表的其他相关信息,例如,查看 mysql 数据库中的 user 表:
mysql> use mysql;
No connection. Trying to reconnect...
Connection id: 20587
Current database: *** NONE ***
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show table status like 'user' \G;
*************************** 1. row ***************************
Name: user
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 3
Avg_row_length: 125
Data_length: 512
Max_data_length: 281474976710655
Index_length: 4096
Data_free: 136
Auto_increment: NULL
Create_time: 2019-07-12 14:45:17
Update_time: 2019-12-20 15:55:44
Check_time: NULL
Collation: utf8_bin
Checksum: NULL
Create_options:
Comment: Users and global privileges
1 row in set (0.00 sec)
ERROR:
No query specified
从查询结果的 Engine 字段可以表明,user表的存储引擎类型为 MyISAM,其他字段在此就不一一说明,如想详细了解可查阅相关文档。
在了解 MySQL 存储引擎前,可以先看看你的 MySQL 数据库支持哪些存储引擎,可通过 show engines 命令查看。我使用的MySQL版本为 5.7.25,查看结果如下图所示:
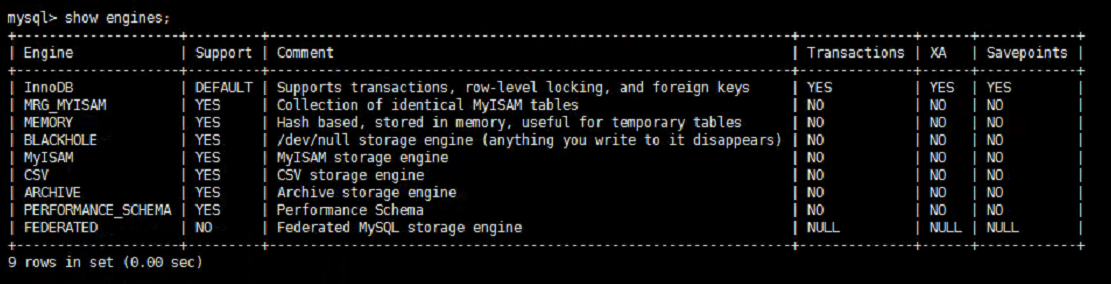
从上述结果可以看出,支持的存储引擎有: InnoDB、Mrg_Myisam、Memory、Blackhole、MyISAM、CSV、 Archive、Performance_Schema、Federated,其中也做了简单的解释说明。
本文只针对 InnoDB、MyISAM 两种最常见的存储引擎进行着重说明,其它存储引擎只做简单说明,详细可查阅官方文档。
1.InnoDB 存储引擎
InnoDB 是 MySQL 的默认事务型引擎,也是最重要、使用最广泛的存储引擎,并且有行级锁定和外键约束。
它被设计用来处理大量的短期(short-lived)事务,短期事务大部分情况是正常提交,很少会被回滚。InnoDB 的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑 InnoDB 引擎。
InnoDB 的适用场景/特性,有以下几种:
- 经常更新的表,适合处理多重并发的更新请求。
- 支持事务。
- 可以从灾难中恢复(通过
bin-log日志等)。 - 外键约束。只有他支持外键。
- 支持自动增加列属性
auto_increment。
2.MyISAM 存储引擎
MyISAM 提供了大量的特性,包括全文检索、压缩等,但不支持事务和行级锁,支持表级锁。
对于只读的数据,或者表较小、可以忍受修复操作的场景,依然可以使用 MyISAM。
MyISAM 的适用场景/特性,有以下几种:
- 不支持事务的设计,但是并不代表着有事务操作的项目不能用
MyISAM存储引擎,完全可以在程序层进行根据自己的业务需求进行相应的控制。 - 不支持外键的表设计。
- 查询速度很快,如果数据库
insert和update的操作比较多的话比较适用。 - 整天 对表进行加锁的场景。
MyISAM极度强调快速读取操作。MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
3.MySQL 内建的其他存储引擎
MySQL 还有一些特殊用途的存储引擎,在一些特殊场景下用起来会很爽的。在 MySQL 新版本中,有些可能因为一些原因已经不再支持了,还有一些会继续支持,但是需要明确地启用后才能使用。
3.1 Archive 存储引擎
Archive 引擎只支持 insert 和 select 操作,并且在 MySQL 5.1 之前连索引都不支持。
Archive 引擎会缓存所有的写并利用 zlib 对插入的行进行压缩,所以比 MyISAM 引擎的磁盘 I/O 更少。但是每次 select 查询都需要进行全表扫描,所以 Archive 更适合日志和数据采集类应用,况且这类应用在做数据分析时往往需要全表扫描。
Archive 引擎支持行级锁和专用的缓冲区,所以可以实现高并发的插入。在一个查询开始直到返回表中存在的所有行之前,Archive 引擎会阻止其他的 select 执行,以实现一致性读。另外,这也实现了批量插入在完成之前对读操作是不看见的。
3.2 Blackhole 存储引擎
Blackhole 引擎没有实现任何的存储机制,它会丢失所有插入的数据,不做任何保存。怪哉,岂不是一无用处?
但是服务器会记录 Blackhole 的日志,所以可以用于复制数据到备库,或者只是简单地记录到日志。这种特殊的存储引擎可以在一些特殊的复制架构和日志审核时发挥作用。
但这种存储引擎的存在,至今还是有些难以理解。
3.3 CSV 存储引擎
CSV 引擎可以将普通的 CSV 文件作为 MySQL 的表来处理,但这种表不支持索引。
CSV 引擎可以在数据库运行时拷入或者拷出文件,可以将 Excel 等电子表格软件中的数据存储为 CSV 文件,然后复制到MySQL数据目录下,就能在 MySQL 中打开使用。同样,如果将数据写入到一个 CSV 引擎表中,其他的外部程序也能立即从表的数据文件中读取 CSV 格式的数据。
因此,CSV 引擎可以作为一种数据交换的机制,是非常有用的。
3.4 Memory 存储引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用 Memory 引擎是非常有用的。Memory 引擎至少比MyISAM 引擎要快一个数量级,因为所有的数据都保存在内存中,不需要进行磁盘 I/O。Memory 引擎的表结构在重启以后还会保留,但数据会丢失。
Memory 引擎在很多场景下可以发挥很好的作用:
- 用于查找或者映射表,例如将邮箱和州名映射的表。
- 用于缓存周期性聚合数据的结果。
- 用于保存数据分析中产生的中间数据。
Memory 引擎支持 Hash 索引,因此查找非常快。虽然 Memory 的速度非常快,但还是无法取代传统的基于磁盘的表。Memory 引擎是表级锁,因此并发吸入的性能较低。
如果 MySQL 在执行查询的过程中,需要使用临时表来保存中间结果,内部使用的临时表就是 Memory 引擎。如果中间结果太大超出了 Memory 的限制,或者含有 BLOB 或 TEXT 字段,则临时表会转换成 MyISAM 的引擎。
看了上面的说明,大家就会经常混淆Memory和临时表了。临时表是指使用
CREATE TEMPORARY TABLE语句创建的表,它可以使用任何存储引擎,因此和Memory不是一回事。临时表只在单个连接中可见,当连接断开时,临时表也将不复存在。
关于临时表和 Memory 引擎的那些事,可参考MySQL · 引擎特性 · 临时表那些事儿。
MySQL 的存储引擎及第三方存储引擎,还有很多,在此就不一一介绍了,后续如有需要,再进一步来谈谈。
4.如何选择合适的存储引擎呢
这么多存储引擎,真是眼花缭乱,我们该如何选择呢?
大部分情况下,都会选择默认的存储引擎—— InnoDB,并且这也是最正确的选择,所以 Oracle 在 MySQL 5.5 版本时终于将 InnoDB 作为默认的存储引擎了。
对于如何选择合适的存储引擎,可以简单地归纳为一句话:”除非需要用到某些 InnoDB 不具备的特性,并且没有其他可以替代,否则都应该优先选择 InnoDB 引擎”。
例如,如果要用到全文检索,建议优先考虑 InnoDB 加上 Sphinx 的组合,而不是使用支持全文检索的 MyISAM。当然,如果不需要用到 InnoDB 的特性,同时其他引擎的特性能够更好地满足需求,就可以考虑一下其他存储引擎。
除非万不得已,建议不要混合使用多种存储引擎,否则可能带来一系列复杂的问题,以及一些潜在的 bug 和边界问题。
如果需要使用不同的存储引擎,建议考虑从以下几个因素进行衡量考虑。
- 事务
- 备份
- 恢复
- 特有的特性
参考文章: